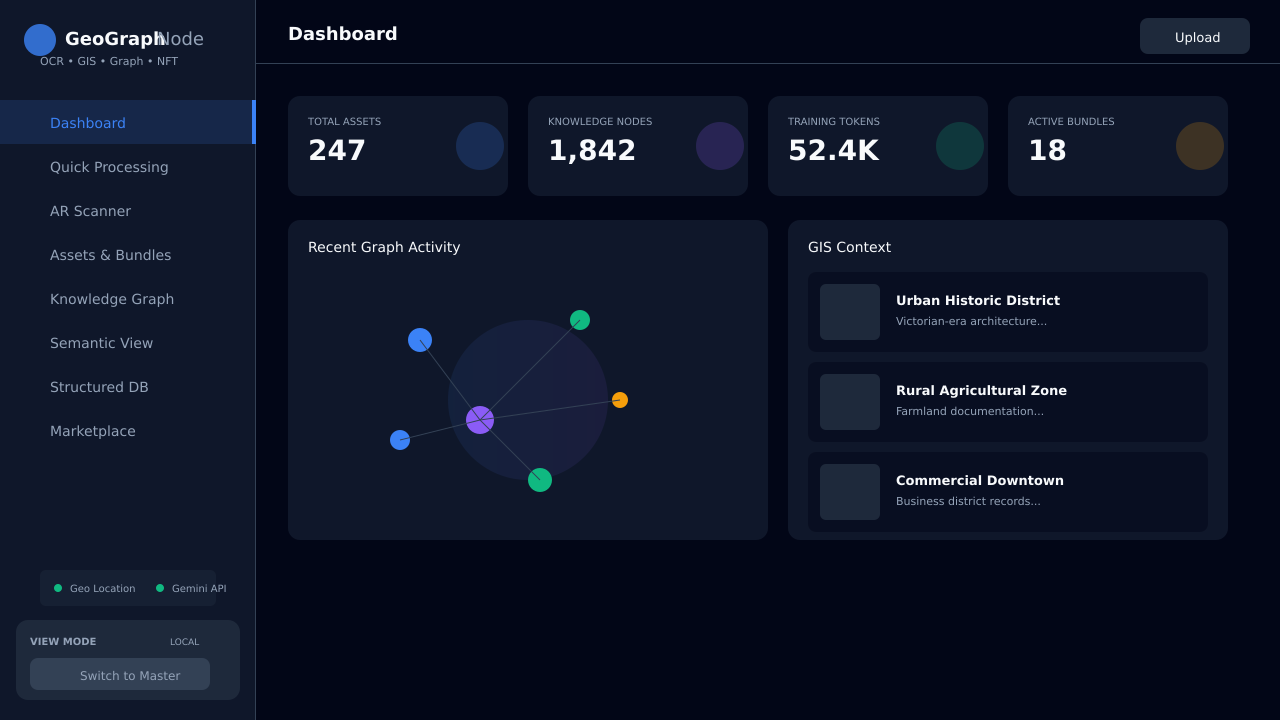
The app
See GeoGraph OCR in action
A full-featured web app that works on desktop and mobile, online and offline.
Built for
GeoGraph OCR uses Google Gemini AI to extract entities, build knowledge graphs, and enrich every scan with GPS metadata — slashing research time from 40 hours to under 5 minutes. Your data, your ownership.
Institutions have spent decades digitizing records, but the data stays locked in flat files — no relationships, no GPS, no structure AI can use. The "data wall" is arriving 2026–27.
Built on Google Gemini 2.5 Flash with a privacy-first, offline-capable architecture — 50,000+ lines of production TypeScript.
Extract text from historical documents, artifacts, signs, and scenery. Multi-language detection built in. Configurable: Gemini, OpenAI, or local models.
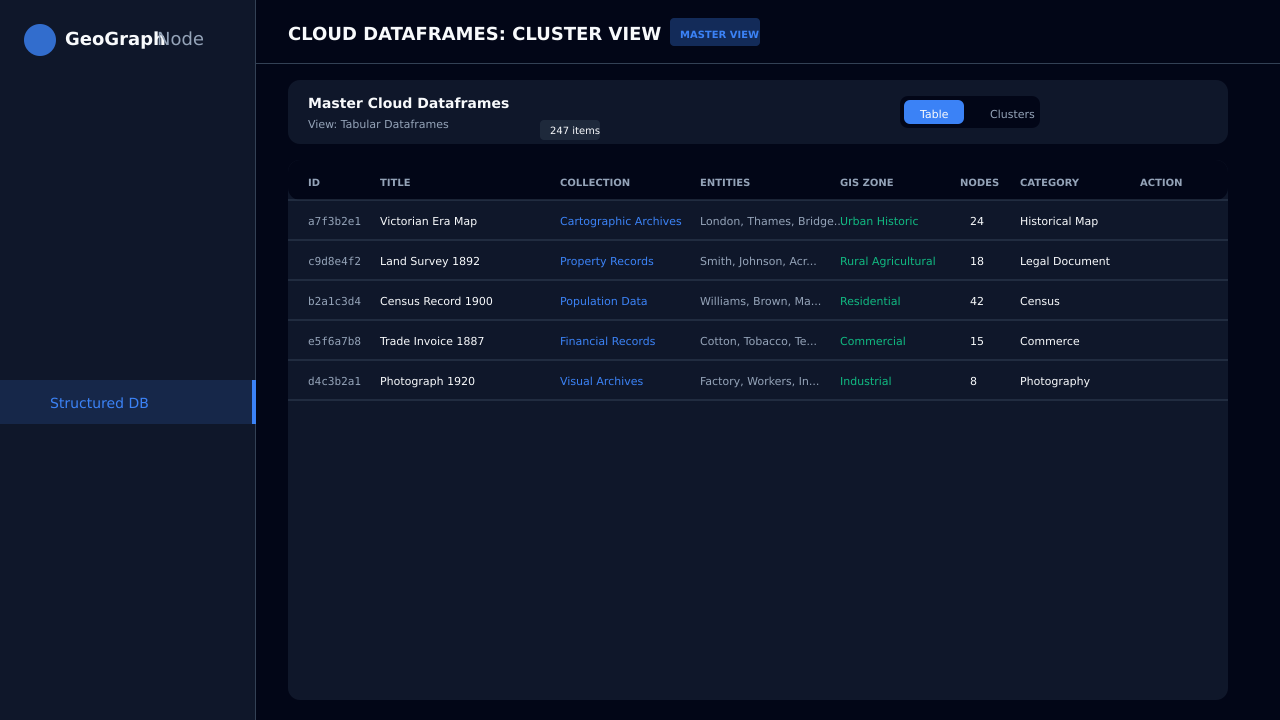
Automatically links entities across documents. Interactive force-directed D3.js visualization. Export to JSON, CSV, or GraphML.
Enrich every scan with GPS coordinates, zone classification, and historical location correlation. Coordinates normalized to WGS84.
Navigate your entire document corpus in an immersive 3D spatial environment powered by Three.js. Semantic clustering groups related records visually.
Semantic NLP detects and merges duplicate entities across thousands of documents automatically. No manual cleanup required.
Process hundreds or thousands of documents in parallel. Server-side queue with pause/resume/cancel controls and real-time progress tracking.
All data stored locally in IndexedDB by default. Cloud sync with Supabase is fully opt-in. End-to-end encryption. You control what gets shared.
License your structured datasets to AI companies. Earn passive income as a fractional owner when your data is licensed via the Web3 marketplace.
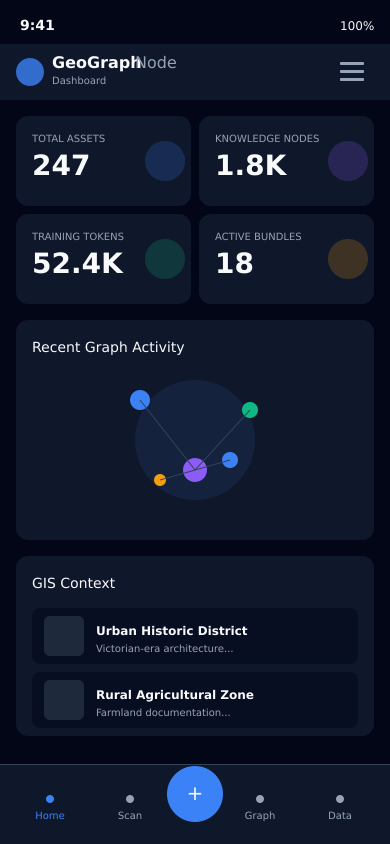
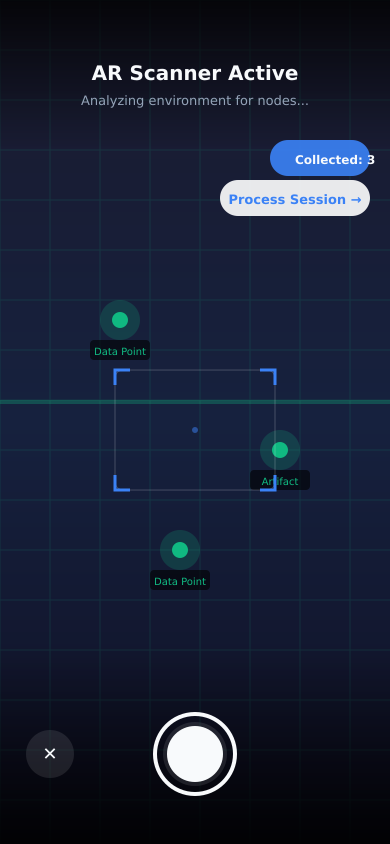
Installable progressive web app with full offline capability. Point your phone at any document and capture it on the spot — museum, estate sale, or archive.
No complex setup. No vendor lock-in. Point, capture, explore.
Point your camera at any document, artifact, sign, or page. GeoGraph captures the image and automatically tags the GPS location.
Gemini 2.5 Flash extracts raw text, then identifies entities (people, places, dates, orgs), temporal era, and semantic relationships.
Entities are linked across your entire corpus in an interactive knowledge graph. Search, query, visualize in 3D, export, or license to AI companies.
A full-featured web app that works on desktop and mobile, online and offline.
Existing tools give you OCR. GeoGraph gives you a structured, user-owned, monetizable knowledge base.
| Capability | Google Vision | AWS Textract | Smithsonian JSON | GeoGraph OCR ✦ |
|---|---|---|---|---|
| Text extraction (OCR) | ✓ | ✓ | Partial | ✓ |
| Entity extraction (NLP) | Limited | Limited | ✗ | ✓ Full |
| Knowledge graph auto-build | ✗ | ✗ | ✗ | ✓ |
| GPS / GIS metadata | ✗ | ✗ | ✗ | ✓ |
| User-owned DB rows (RLS) | ✗ Vendor lock | ✗ Vendor lock | ✗ | ✓ Supabase RLS |
| Offline-first PWA | ✗ | ✗ | ✗ | ✓ |
| AI training data monetization | ✗ | ✗ | ✗ | ✓ Marketplace |
| 3D spatial visualization | ✗ | ✗ | ✗ | ✓ Three.js |
From solo researchers to enterprise institutions — if you work with documents, this is for you.
Process entire collections in hours. Auto-extract entities, build provenance graphs, and make holdings searchable by anyone.
~50K institutions globallyStop spending 40 hours manually cataloging each collection. Let AI extract the knowledge so you can focus on the insights.
10M+ knowledge workersAutomate discovery. Extract key entities from thousands of documents in minutes. Full confidentiality with offline-first storage.
~1.3M firms globallyBuy structured, verified, historically rich training datasets from the marketplace — the kind of data that pushes models past the data wall.
$1.2B market opportunityStart for free with your own API keys. Scale as your corpus grows. Cancel anytime.
For individuals and hobbyists starting their first collections.
For researchers, journalists, and small archives needing cloud sync and advanced NLP.
For institutions, museums, and enterprise archival teams needing white-glove service.
Processing credits included on paid plans. Free plan requires your own Gemini / OpenAI API key.
GeoGraph is the only OCR platform that gives you fractional ownership of the data you create. When AI companies license the corpus, revenue flows back to contributors — proportional to what you captured.
Photograph records at museums, archives, estate sales, workplaces. Every scan is structured and recorded in your account.
Your structured records are minted as GARD Data Shards — ERC-1155 tokens on-chain. You hold fractional ownership of the corpus.
OpenAI, Anthropic, and others buy structured historical datasets from the marketplace. Revenue splits proportionally to shard holders.
To grow your share, capture more records. Visit museums. Explore archives. Build a data portfolio while living your life.
Pre-seed round — 8–10% equity to structure the first 100 archival collections and prove the AI licensing model. The AI training data crisis is real, and the window to own this market is closing.
Any photo or scan — handwritten letters, printed records, historical maps, newspaper clippings, legal documents, safety posters, artifacts, and museum placards. Multi-language detection covers Latin scripts, CJK characters, and more.
Yes. GeoGraph OCR is an offline-first PWA. All data is stored in IndexedDB on your device. Cloud sync with Supabase is fully opt-in — your data never has to leave your device unless you choose to enable it.
By default everything stays on your device. When you enable cloud sync, data is stored in your own Supabase instance with Row-Level Security — even we cannot read your rows. OCR API calls go directly from your browser to your AI provider using your own key.
When you capture and structure documents, you can opt-in to mint them as GARD Data Shards — ERC-1155 NFTs representing fractional ownership of the corpus. When AI companies license datasets, revenue is distributed proportionally to shard holders. Think royalties for the data you help create.
Yes. Export your entire graph as JSON, CSV, or GraphML. Pro users also get structured AI-training dataset exports compatible with Hugging Face and OpenAI fine-tuning formats.
On the Free plan, yes — bring your own Gemini or OpenAI key (Gemini 2.5 Flash has a generous free tier). On paid plans, processing credits are included. Local model support via Ollama and LM Studio is also available.
Join researchers, archivists, and enterprises transforming their collections with GeoGraph OCR.